可能每一个前端工程师都想要理解浏览器的工作原理。
我们希望知道从在浏览器地址栏中输入url到页面展现的短短几秒内浏览器究竟做了什么;
我们希望了解平时常常听说的各种代码优化方案是究竟为什么能起到优化的作用;
我们希望更细化的了解浏览器的渲染流程。
浏览器的多进程架构
一个好的程序常常被划分为几个相互独立又彼此配合的模块,浏览器也是如此,以Chrome为例,它由多个进程组成,每个进程都有自己核心的职责,它们相互配合完成浏览器的整体功能,每个进程中又包含多个线程,一个进程内的多个线程也会协同工作,配合完成所在进程的职责。
对一些前端开发同学来说,进程和线程的概念可能会有些模糊,为了更好的理解浏览器的多进程架构,这里我们简单讨论一下进程和线程。
进程(process)和线程(thread)
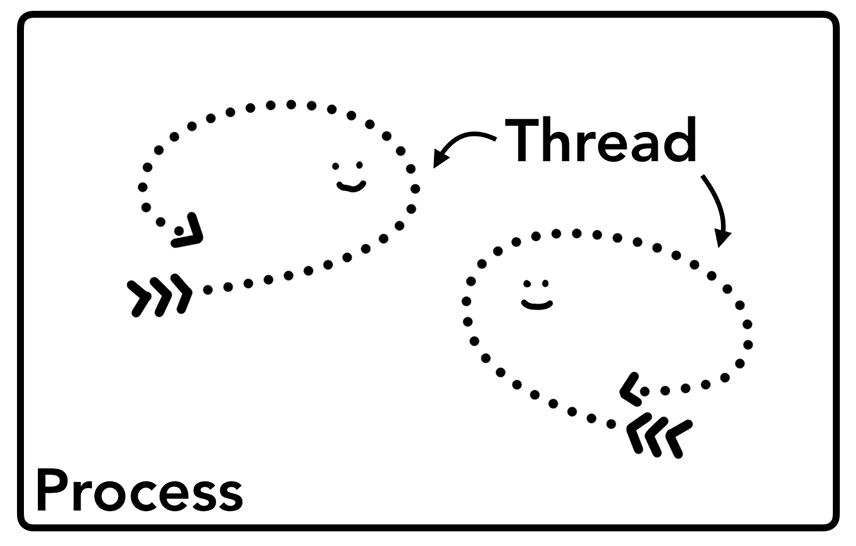
进程就像是一个有边界的生产厂间,而线程就像是厂间内的一个个员工,可以自己做自己的事情,也可以相互配合做同一件事情。
当我们启动一个应用,计算机会创建一个进程,操作系统会为进程分配一部分内存,应用的所有状态都会保存在这块内存中,应用也许还会创建多个线程来辅助工作,这些线程可以共享这部分内存中的数据。如果应用关闭,进程会被终结,操作系统会释放相关内存。更生动的示意图如下:
一个进程还可以要求操作系统生成另一个进程来执行不同的任务,系统会为新的进程分配独立的内存,两个进程之间可以使用IPC(InterProcessCommunication)进行通信。很多应用都会采用这样的设计,如果一个工作进程反应迟钝,重启这个进程不会影响应用其它进程的工作。
如果对进程及线程的理解还存在疑惑,可以参考下述文章:
浏览器的架构
有了上面的知识做铺垫,我们可以更合理的讨论浏览器的架构了,其实如果要开发一个浏览器,它可以是单进程多线程的应用,也可以是使用IPC通信的多进程应用。
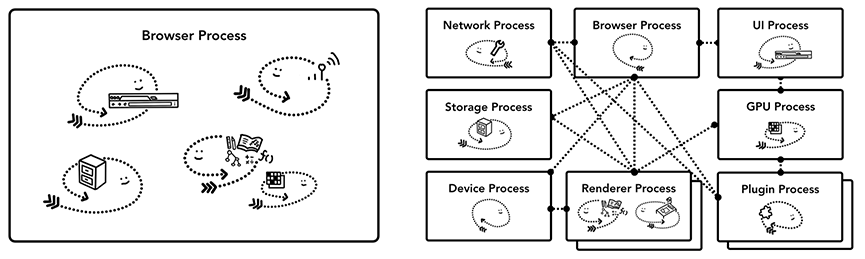
不同浏览器的架构模型
不同浏览器采用了不同的架构模式,这里并不存在标准,本文以Chrome为例进行说明:
Chrome采用多进程架构,其顶层存在一个Browserprocess用以协调浏览器的其它进程。
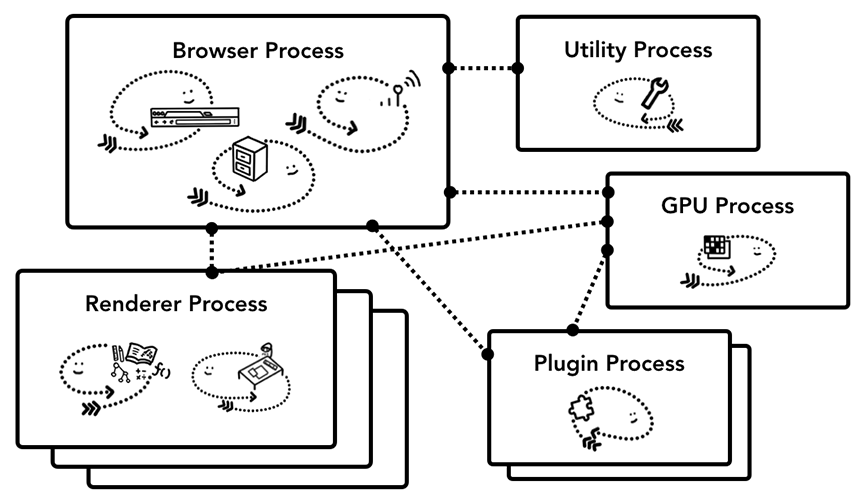
Chrome的不同进程
具体说来,Chrome的主要进程及其职责如下:
BrowserProcess:
负责包括地址栏,书签栏,前进后退按钮等部分的工作;
负责处理浏览器的一些不可见的底层操作,比如网络请求和文件访问;
RererProcess:
负责一个tab内关于网页呈现的所有事情
PluginProcess:
负责控制一个网页用到的所有插件,如flash
GPUProcess
负责处理GPU相关的任务
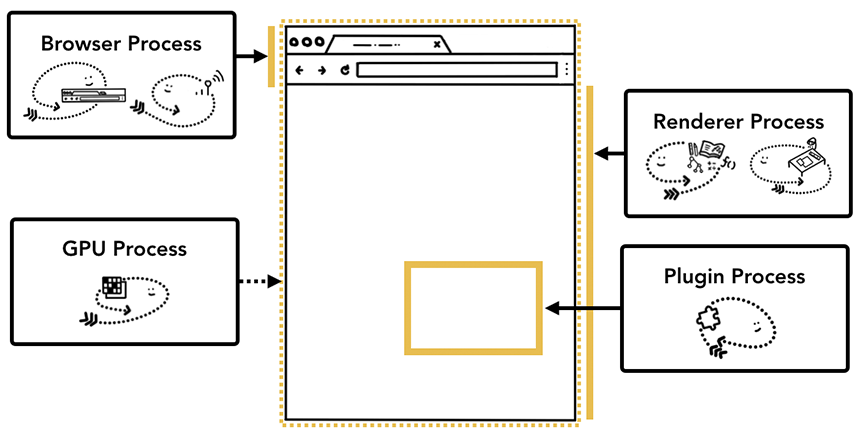
不同进程负责的浏览器区域示意图
通过「页面右上角的三个点点点—更多工具—任务管理器」即可打开相关面板。
Chrome多进程架构的优缺点
优点
某一渲染进程出问题不会影响其他进程
更为安全,在系统层面上限定了不同进程的权限
缺点
由于不同进程间的内存不共享,不同进程的内存常常需要包含相同的内容。
为了节省内存,Chrome限制了最多的进程数,最大进程数量由设备的内存和CPU能力决定,当达到这一限制时,新打开的Tab会共用之前同一个站点的渲染进程。
Chrome把浏览器不同程序的功能看做服务,这些服务可以方便的分割为不同的进程或者合并为一个进程。以BroswerProcess为例,如果Chrome运行在强大的硬件上,它会分割不同的服务到不同的进程,这样Chrome整体的运行会更加稳定,但是如果Chrome运行在资源贫瘠的设备上,这些服务又会合并到同一个进程中运行,这样可以节省内存,示意图如下。
iframe的渲染–SiteIsolation
在上面的进程图中我们还可以看到一些进程下还存在着Subframe,这就是SiteIsolation机制作用的结果。
SiteIsolation机制从Chrome67开始默认启用。这种机制允许在同一个Tab下的跨站iframe使用单独的进程来渲染,这样会更为安全。
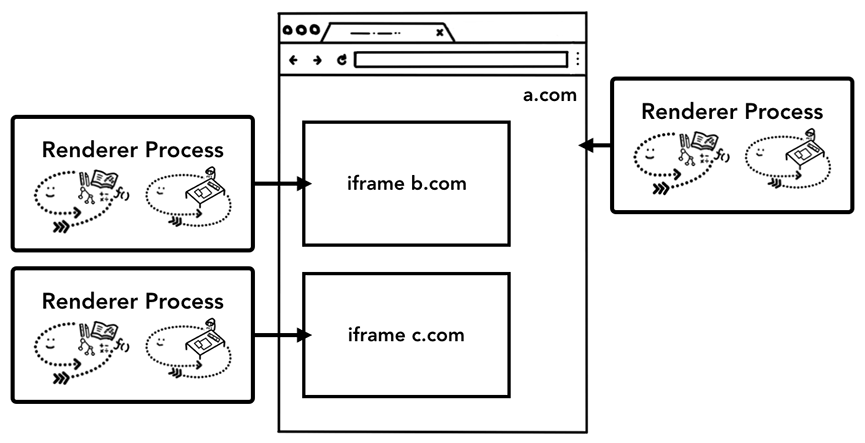
iframe会采用不同的渲染进程
SiteIsolation被大家看做里程碑式的功能,其成功实现是多年工程努力的结果。SiteIsolation不是简单的叠加多个进程。这种机制在底层改变了iframe之间通信的方法,Chrome的其它功能都需要做对应的调整,比如说devtools需要相应的支持,甚至Ctrl+F也需要支持。关于SiteIsolation的更多内容可参考下述链接:
介绍完了浏览器的基本架构模式,接下来我们看看一个常见的导航过程对浏览器来说究竟发生了什么。
导航过程发生了什么
也许大多数人使用Chrome最多的场景就是在地址栏输入关键字进行搜索或者输入地址导航到某个网站,我们来看看浏览器是怎么看待这个过程的。
我们知道浏览器Tab外的工作主要由BrowserProcess掌控,BrowserProcess又对这些工作进一步划分,使用不同线程进行处理:
UIthread:控制浏览器上的按钮及输入框;
networkthread:处理网络请求,从网上获取数据;
storagethread:控制文件等的访问;
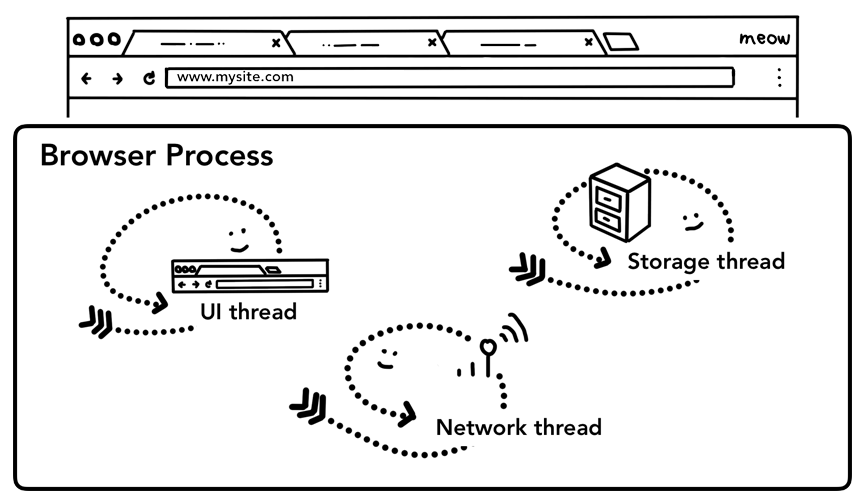
浏览器主进程中的不同线程
1.处理输入
UIthread需要判断用户输入的是URL还是query;
2.开始导航
networkthread会执行DNS查询,随后为请求建立TLS连接。
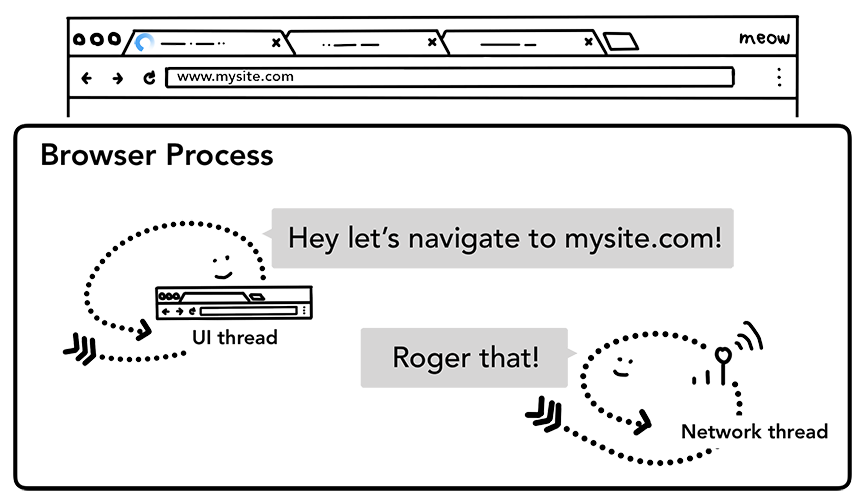
UIthread通知Networkthread加载相关信息
如果networkthread接收到了重定向请求头如301,networkthread会通知UIthread服务器要求重定向,之后,另外一个URL请求会被触发。
3.读取响应
当请求响应返回的时候,networkthread会依据Content-Type及MIMETypesniffing判断响应内容的格式。
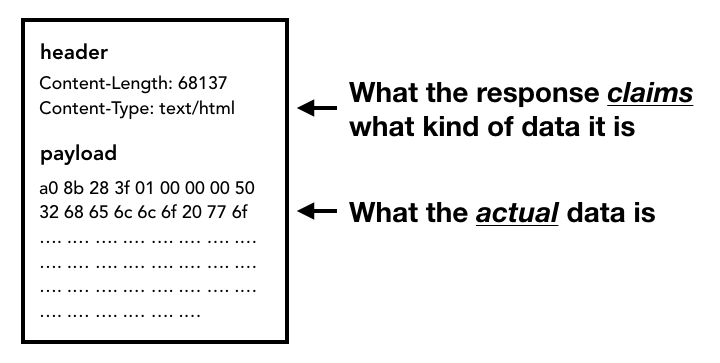
判断响应内容的格式
如果响应内容的格式是HTML,下一步将会把这些数据传递给rererprocess,如果是zip文件或者其它文件,会把相关数据传输给下载管理器。
SafeBrowsing检查也会在此时触发,如果域名或者请求内容匹配到已知的恶意站点,networkthread会展示一个警告页。此外CORB检测也会触发确保敏感数据不会被传递给渲染进程。
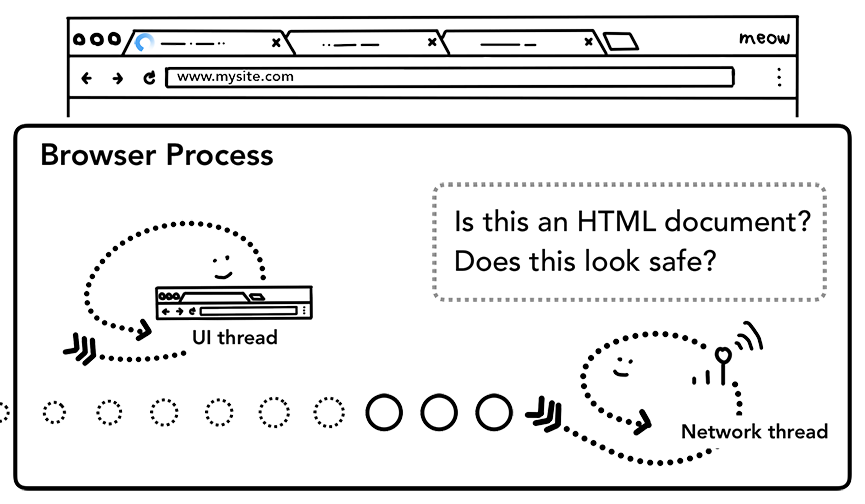
4.查找渲染进程
当上述所有检查完成,networkthread确信浏览器可以导航到请求网页,networkthread会通知UIthread数据已经准备好,UIthread会查找到一个rererprocess进行网页的渲染。

收到Networkthread返回的数据后,UIthread查找相关的渲染进程
由于网络请求获取响应需要时间,这里其实还存在着一个加速方案。当UIthread发送URL请求给networkthread时,浏览器其实已经知道了将要导航到那个站点。UIthread会并行的预先查找和启动一个渲染进程,如果一切正常,当networkthread接收到数据时,渲染进程已经准备就绪了,但是如果遇到重定向,准备好的渲染进程也许就不可用了,这时候就需要重启一个新的渲染进程。
5.确认导航
进过了上述过程,数据以及渲染进程都可用了,BrowserProcess会给rererprocess发送IPC消息来确认导航,一旦BrowserProcess收到rererprocess的渲染确认消息,导航过程结束,页面加载过程开始。
此时,地址栏会更新,展示出新页面的网页信息。historytab会更新,可通过返回键返回导航来的页面,为了让关闭tab或者窗口后便于恢复,这些信息会存放在硬盘中。
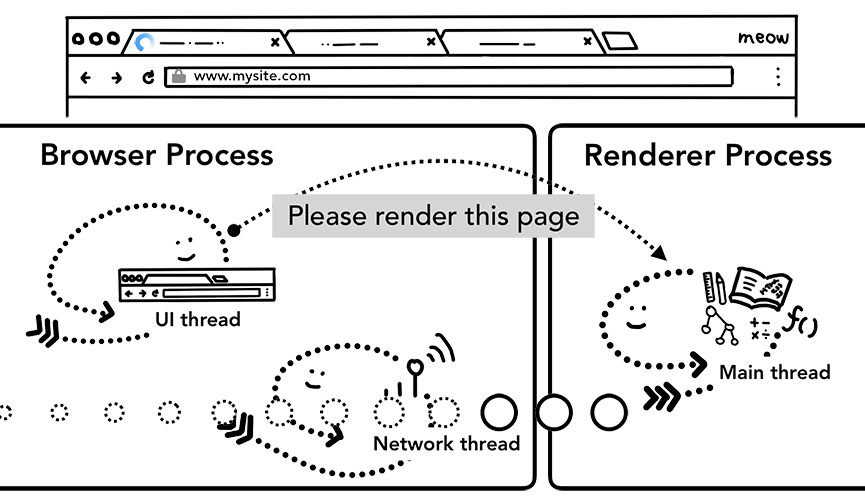
6.额外的步骤
一旦导航被确认,rererprocess会使用相关的资源渲染页面,下文中我们将重点介绍渲染流程。当rererprocess渲染结束(渲染结束意味着该页面内的所有的页面,包括所有iframe都触发了onload时),会发送IPC信号到Browserprocess,UIthread会停止展示tab中的spinner。
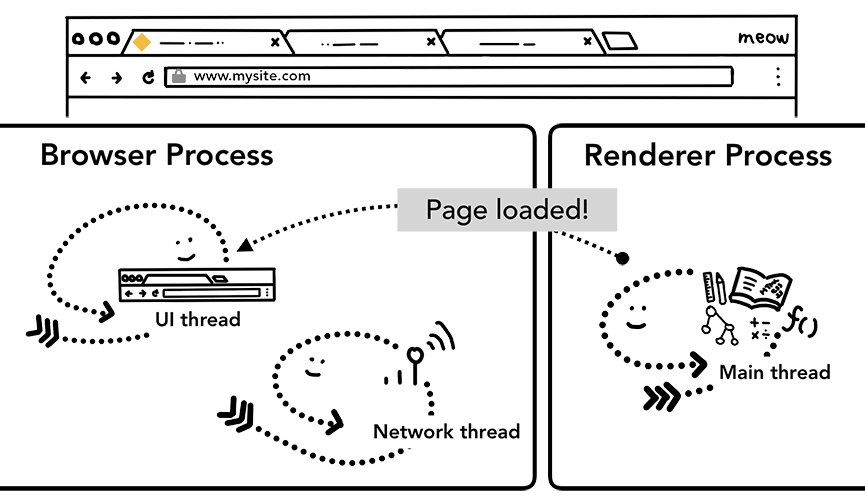
RererProcess发送IPC消息通知browserprocess页面已经加载完成。
当然上面的流程只是网页首帧渲染完成,在此之后,客户端依旧可下载额外的资源渲染出新的视图。
在这里我们可以明确一点,所有的JS代码其实都由rererProcess控制的,所以在你浏览网页内容的过程大部分时候不会涉及到其它的进程。不过也许你也曾经监听过beforeunload事件,这个事件再次涉及到BrowserProcess和rererProcess的交互,当当前页面关闭时(关闭Tab,刷新等等),BrowserProcess需要通知rererProcess进行相关的检查,对相关事件进行处理。
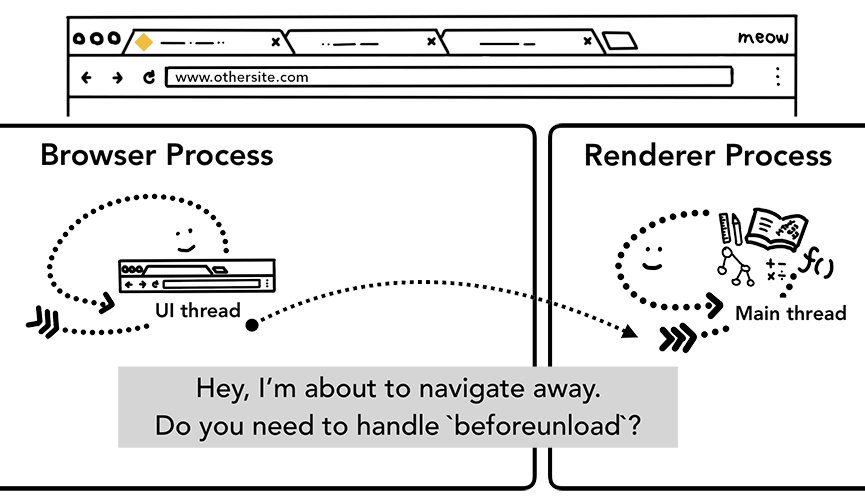
浏览器进程发送IPC消息给渲染进程,通知要离开当前网站了
如果导航到新的网站,会启用一个新的rerprocess来处理新页面的渲染,老的进程会留下来处理类似unload等事件。
关于页面的生命周期,更多内容可参考PageLifecycleAPI。
浏览器进程发送IPC消息到新的渲染进程通知渲染新的页面,同时通知旧的渲染进程卸载。
除了上述流程,有些页面还拥有ServiceWorker(服务工作线程),ServiceWorker让开发者对本地缓存及判断何时从网络上获取信息有了更多的控制权,如果ServiceWorker被设置为从本地cache中加载数据,那么就没有必要从网上获取更多数据了。
值得注意的是serviceworker也是运行在渲染进程中的JS代码,因此对于拥有ServiceWorker的页面,上述流程有些许的不同。
当有ServiceWorker被注册时,其作用域会被保存,当有导航时,networkthread会在注册过的ServiceWorker的作用域中检查相关域名,如果存在对应的Serviceworker,UIthread会找到一个rererprocess来处理相关代码,ServiceWorker可能会从cache中加载数据,从而终止对网络的请求,也可能从网上请求新的数据。

ServiceWorker依据具体情形做处理。
关于ServiceWorker的更多内容可参考:
如果ServiceWorker最终决定通过网上获取数据,Browser进程和rerer进程的交互其实会延后数据的请求时间。NavigationPreload是一种与ServiceWorker并行的加速加载资源的机制,服务端通过请求头可以识别这类请求,而做出相应的处理。
更多内容可参考:
渲染进程是如何工作的?
渲染进程几乎负责Tab内的所有事情,渲染进程的核心目的在于转换HTMLCSSJS为用户可交互的web页面。渲染进程中主要包含以下线程:
渲染进程包含的线程
1.主线程Mainthread
2.工作线程Workerthread
3.排版线程Compositorthread
4.光栅线程Rasterthread
后文我们将逐步介绍不同线程的职责,在此之前我们先看看渲染的流程。
1.构建DOM
当渲染进程接收到导航的确认信息,开始接受HTML数据时,主线程会解析文本字符串为DOM。
渲染html为DOM的方法由HTMLStandard定义。
2.加载次级的资源
网页中常常包含诸如图片,CSS,JS等额外的资源,这些资源需要从网络上或者cache中获取。主进程可以在构建DOM的过程中会逐一请求它们,为了加速preloadscanner会同时运行,如果在html中存在imglink等标签,preloadscanner会把这些请求传递给Browserprocess中的networkthread进行相关资源的下载。
3.JS的下载与执行
当遇到script标签时,渲染进程会停止解析HTML,而去加载,解析和执行JS代码,停止解析html的原因在于JS可能会改变DOM的结构(使用诸如()等API)。
不过开发者其实也有多种方式来告知浏览器应对如何应对某个资源,比如说如果在script标签上添加了async或defer等属性,浏览器会异步的加载和执行JS代码,而不会阻塞渲染。更多的方法可参考ResourcePrioritization–GettingtheBrowsertoHelpYou。
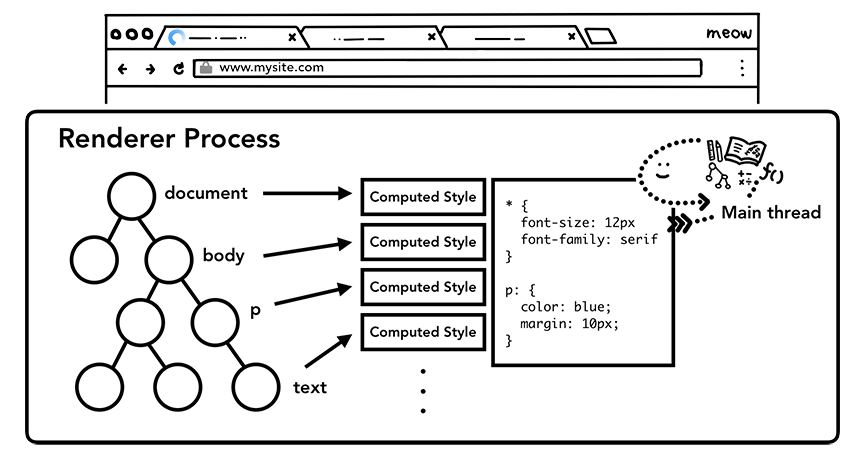
4.样式计算
仅仅渲染DOM还不足以获知页面的具体样式,主进程还会基于CSS选择器解析CSS获取每一个节点的最终的计算样式值。即使不提供任何CSS,浏览器对每个元素也会有一个默认的样式。

渲染进程主线程计算每一个元素节点的最终样式值
5.获取布局
想要渲染一个完整的页面,除了获知每个节点的具体样式,还需要获知每一个节点在页面上的位置,布局其实是找到所有元素的几何关系的过程。其具体过程如下:
通过遍历DOM及相关元素的计算样式,主线程会构建出包含每个元素的坐标信息及盒子大小的布局树。布局树和DOM树类似,但是其中只包含页面可见的元素,如果一个元素设置了display:none,这个元素不会出现在布局树上,伪元素虽然在DOM树上不可见,但是在布局树上是可见的。
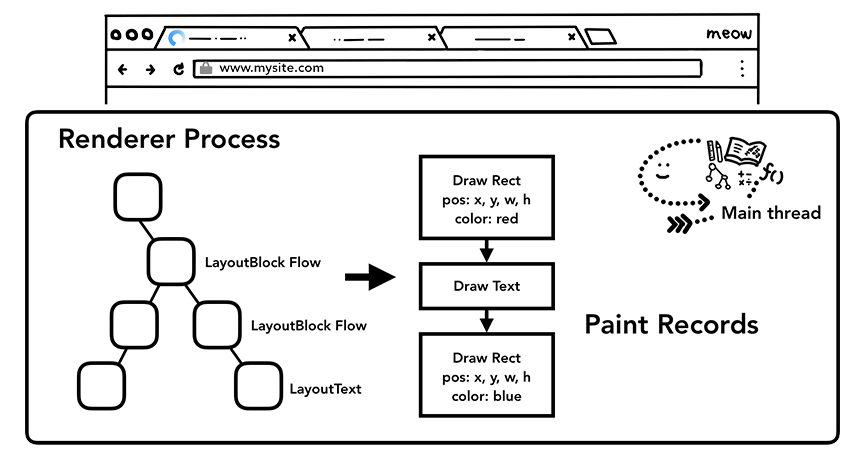
6.绘制各元素
即使知道了不同元素的位置及样式信息,我们还需要知道不同元素的绘制先后顺序才能正确绘制出整个页面。在绘制阶段,主线程会遍历布局树以创建绘制记录。绘制记录可以看做是记录各元素绘制先后顺序的笔记。
主线程依据布局树构建绘制记录
7.合成帧
熟悉PS等绘图软件的童鞋肯定对图层这一概念不陌生,现代Chrome其实利用了这一概念来组合不同的层。
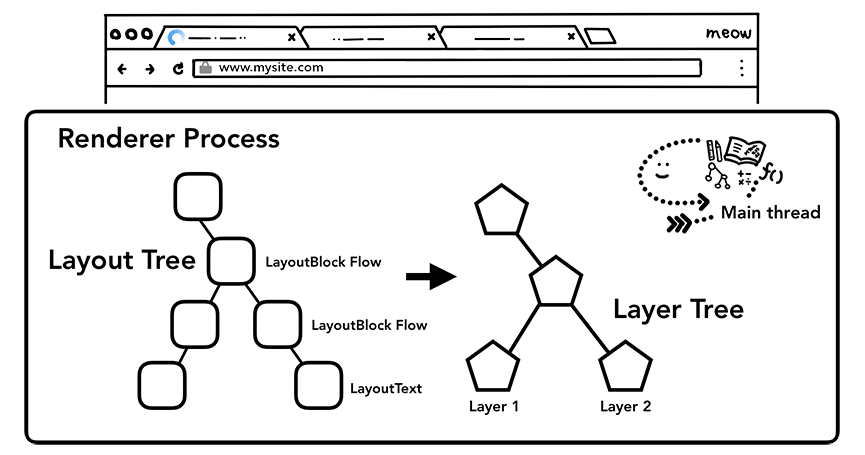
复合是一种分割页面为不同的层,并单独栅格化,随后组合为帧的技术。不同层的组合由compositor线程(合成器线程)完成。
主线程会遍历布局树来创建层树(layertree),添加了will-changeCSS属性的元素,会被看做单独的一层。
主线程遍历布局树生成层树
你可能会想给每一个元素都添加上will-change,不过组合过多的层也许会比在每一帧都栅格化页面中的某些小部分更慢。为了更合理的使用层,可参考坚持仅合成器的属性和管理层计数。
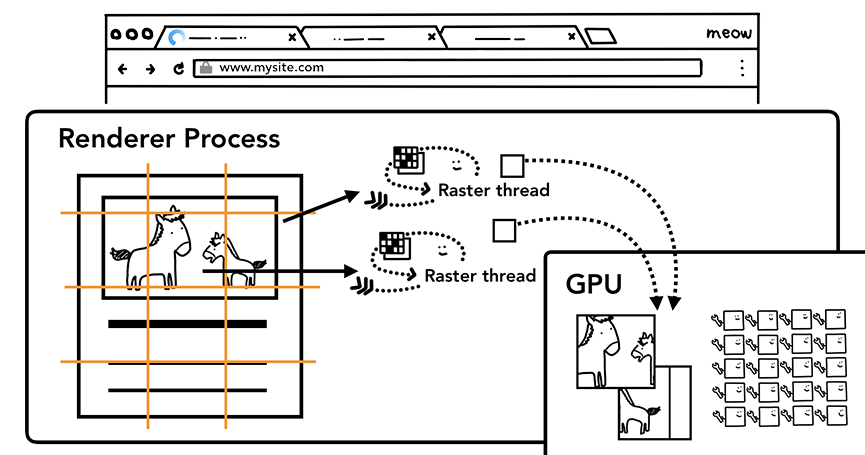
一旦层树被创建,渲染顺序被确定,主线程会把这些信息通知给合成器线程,合成器线程会栅格化每一层。有的层的可以达到整个页面的大小,因此,合成器线程将它们分成多个磁贴,并将每个磁贴发送到栅格线程,栅格线程会栅格化每一个磁贴并存储在GPU显存中。
栅格线程会栅格化每一个磁贴并存储在GPU显存中
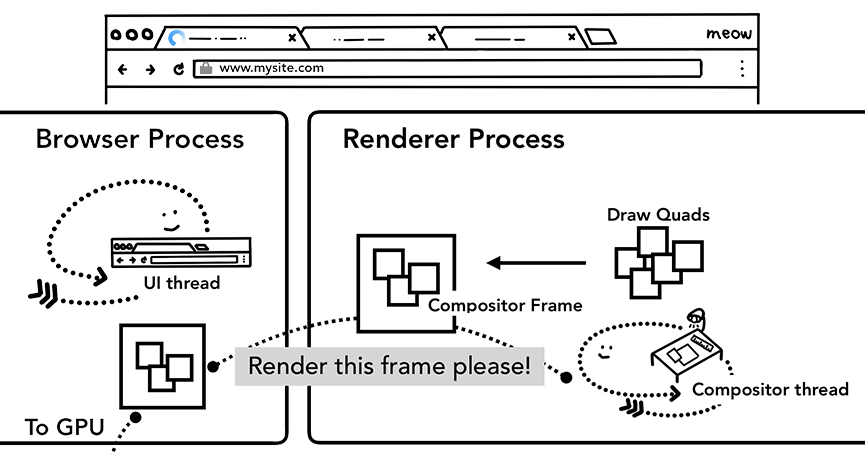
一旦磁贴被光栅化,合成器线程会收集称为绘制四边形的磁贴信息以创建合成帧。
合成帧随后会通过IPC消息传递给浏览器进程,由于浏览器的UI改变或者其它拓展的渲染进程也可以添加合成帧,这些合成帧会被传递给GPU用以展示在屏幕上,如果滚动发生,合成器线程会创建另一个合成帧发送给GPU。
合成器线程会发送合成帧给GPU渲染
合成器的优点在于,其工作无关主线程,合成器线程不需要等待样式计算或者JS执行,这就是为什么合成器相关的动画最流畅,如果某个动画涉及到布局或者绘制的调整,就会涉及到主线程的重新计算,自然会慢很多。
浏览器对事件的处理
浏览器通过对不同事件的处理来满足各种交互需求,这一部分我们一起看看从浏览器的视角,事件是什么,在此我们先主要考虑鼠标事件。
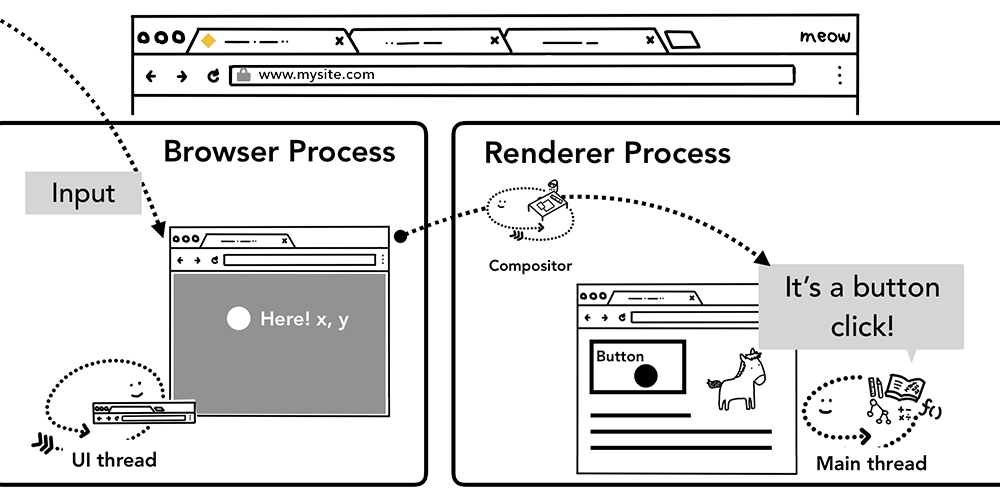
当用户在屏幕上触发诸如touch等手势时,首先收到手势信息的是Browserprocess,不过Browserprocess只会感知到在哪里发生了手势,对tab内内容的处理是还是由渲染进程控制的。
事件发生时,浏览器进程会发送事件类型及相应的坐标给渲染进程,渲染进程随后找到事件对象并执行所有绑定在其上的相关事件处理函数。
事件从浏览器进程传送给渲染进程
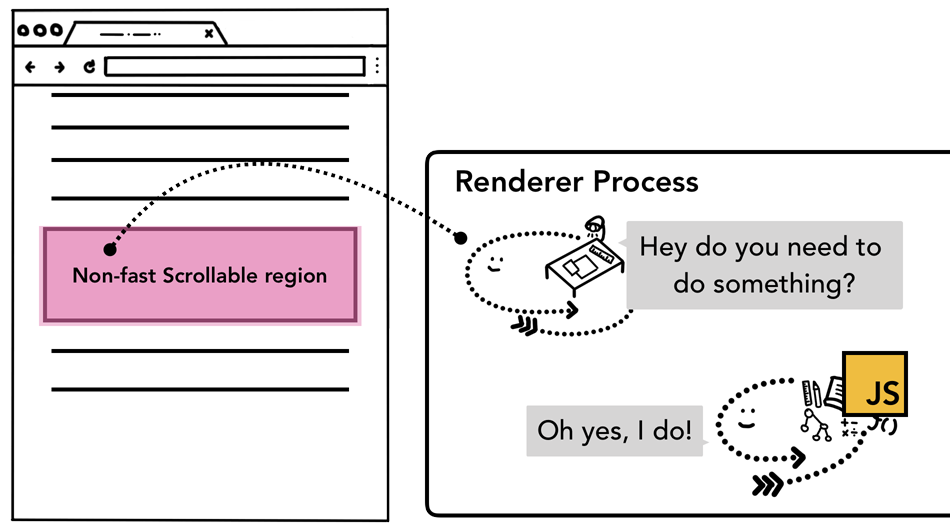
前文中,我们提到过合成器可以独立于主线程之外通过合成栅格化层平滑的处理滚动。如果页面中没有绑定相关事件,组合器线程可以独立于主线程创建组合帧。如果页面绑定了相关事件处理器,主线程就不得不出来工作了。这时候合成器线程会怎么处理呢?
这里涉及到一个专业名词「理解非快速滚动区域(non-fastscrollableregion)」由于执行JS是主线程的工作,当页面合成时,合成器线程会标记页面中绑定有事件处理器的区域为non-fastscrollableregion,如果存在这个标注,合成器线程会把发生在此处的事件发送给主线程,如果事件不是发生在这些区域,合成器线程则会直接合成新的帧而不用等到主线程的响应。
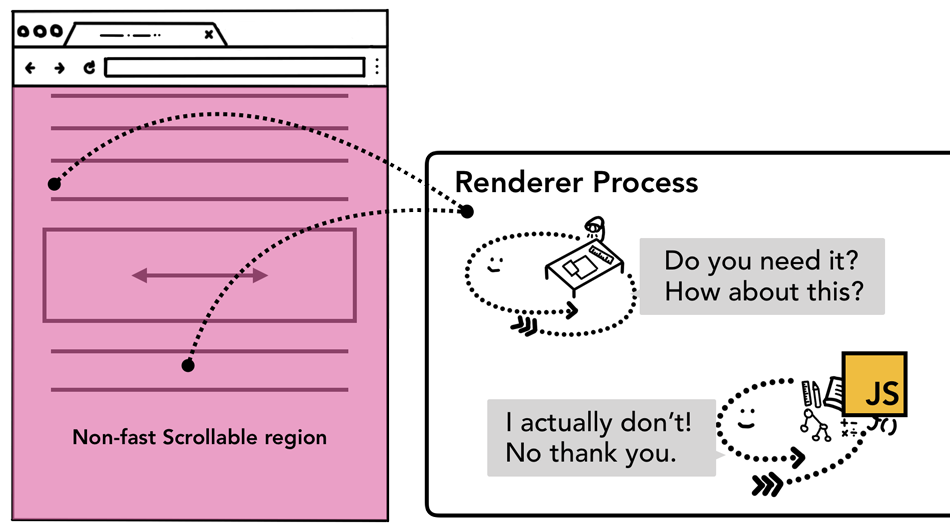
涉及non-fastscrollableregion的事件,合成器线程会通知主线程进行相关处理。
web开发中常用的事件处理模式是事件委托,基于事件冒泡,我们常常在最顶层绑定事件:
复制代码
('touchstart',event={if(===area){();}});上述做法很常见,但是如果从浏览器的角度看,整个页面都成了non-fastscrollableregion了。

为了防止这种情况,我们可以为事件处理器传递passive:true做为参数,这样写就能让浏览器即监听相关事件,又让组合器线程在等等主线程响应前构建新的组合帧。
复制代码
('touchstart',event={if(===area){()}},{passive:true});不过上述写法可能又会带来另外一个问题,假设某个区域你只想要水平滚动,使用passive:true可以实现平滑滚动,但是垂直方向的滚动可能会先于()发生,此时可以通过来防止这种情况。
复制代码
('pointermove',event={if(){();//blockthenativescroll/**dowhatyouwanttheapplicationtodohere*/}},{passive:true});也可以使用css属性touch-action来完全消除事件处理器的影响,如:
复制代码
#area{touch-action:pan-x;}查找到事件对象
当组合器线程发送输入事件给主线程时,主线程首先会进行命中测试(hittest)来查找对应的事件目标,命中测试会基于渲染过程中生成的绘制记录(paintrecords)查找事件发生坐标下存在的元素。
主线程依据绘制记录查找事件相关元素。
事件的优化
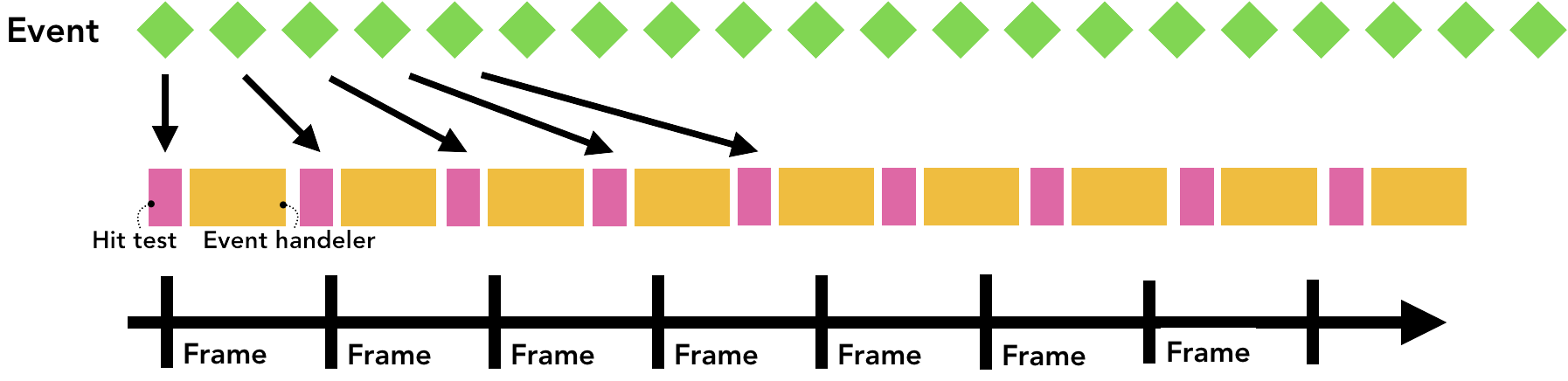
一般我们屏幕的刷新速率为60fps,但是某些事件的触发量会不止这个值,出于优化的目的,Chrome会合并连续的事件(如wheel,mousewheel,mousemove,pointermove,touchmove),并延迟到下一帧渲染时候执行。
而如keydown,keyup,mouseup,mousedown,touchstart,和touch等非连续性事件则会立即被触发。
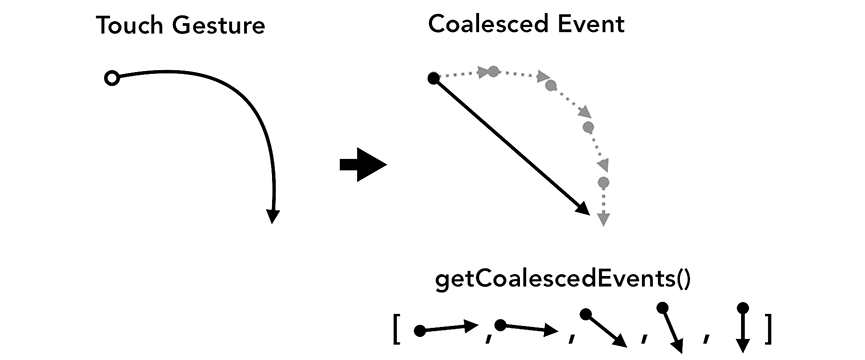
Chrome会合并连续事件到下一帧触发。
合并事件虽然能提示性能,但是如果你的应用是绘画等,则很难绘制一条平滑的曲线了,此时可以使用getCoalescedEventsAPI来获取组合的事件。示例代码如下:
复制代码
('pointermove',event={constevents=();for(leteventofevents){constx=;consty=;//drawalineusingxandycoordinates.}});花了好久来整理上面的内容,整理的过程收获还挺大的,也希望这篇笔记能对你有所启发,如果有任何疑问,欢迎一起来讨论。
本文经作者授权转载,原文链接为: